


A cook's tour through using elasticsearch: instant postcode search and road name search
A good part of the work involved in building bookingDialog's taxi booking engine deals with indexing UK addresses that are used for pickup and drop off locations. There are several tasks involved, but the most basic is finding an address or a postocde and associate it to longitude and latitude coordinates of a point on the map; i.e. geocoding. There are several APIs that do just that; for instance, there is google's maps api, bing's api, or mapquest's api to name just a few. All of these do a fantastic job at finding the correct spot, yet their T&Cs place several limitation on what you do with their free versions.
The alternative is to build a DIY geocoder and address lookup. All we need is some raw address-dataset and a way to index it so that information is readily retrieved. To our knowledge, the most complete dataset of UK addresses is contained in the PAF file (Postal Address File). It contains map coordinates for UK postcodes as well as coordinates for road names, building names, flat and house numbers. The file isn't distributed for free. It is licensed by Royal Mail and has several pricing options available.
Ordnance Survey has released a considerable subset of the PAF under an attribution only license. The information is scattered throughout several files; but, there are two distinct datasets that we can make good use of. The first is the CSV file that contains a mapping from postcodes to geo coordinates (Codepoint Open) and the second is the file containing all UK road names (OS Locator) along with the bounding box of each road object. There are no coordinates for flat numbers or building names contained in either file and data isn't linked in some useful way. For instance, given a postcode it is not possible to tell which road it belongs to.
Objective and Scope
With the help of elasticsearch, we can build a geocoder and address lookup, adequate for our purposes, that is rivaling expensive geo APIs. If we hook up our DIY search engine to an instant HTML search box the we've got ourselves a very capable business solution indeed.
The elasticsearch database can be populated by a 50-something-liner of python code, which indexes the whole dataset in exactly the way we need. However, we don't have such a script. This article is about getting the grips with elasticsearch: what we will do is index an initial set of data and iteratively improve and reindex it until it is fit for purpose.
Datasets, tools and downloads
Download Codepoint Open and OS Locator in CSV format. Our software development firm is located at 1 Dock Road E161AG London. This is the data that we have:
OS Locator: Road Names
| Name | Class | CenterX | CenterY | MinX | MinY | MaxX | MaxY | Settlement | Locality | Co Unit | Local Auth | Tile | ... |
| DOCK ROAD | 539987 | 180471 | 539978 | 539996 | 180461 | 180480 | LONDON | Royal Docks | Greater London Authority | Newham London Boro | TQ38SE | ... |
The road object is bound by a box which is defined by coordinates (easting and northing) where min is the southwest corner of the box, max is the northeast corner and center is the centerpoint of the road object.
Codepoint Open and Doogal - Postcodes
| Postcode | Quality | Easting | Northing | Country Code | NHS regional auth | NHS health auth | County code | District code | Ward Code |
| E16 1AG | 10 | 539995 | 180487 | E92000001 | E19000003 | E18000007 | E09000025 | E09000025 | E05000491 |
The Codepoint Open files have coordinates for each postcode in the UK. Notice that the example above contains district and ward names. These are however provides as IDs; the actual names are provided in a separate file. The guys over at doogal distribute a postcode dataset that merges most Codepoint Open data into a single file. As an added bonus, eastings and northings are translated into longitude and latitude coordinates. This is the file we will use from now on. You can get a copy here. Here's how this looks like.
| Postcode | Latitude | Longitude | Easting | Northing | GridRef | County | District | Ward | District Code | Ward Code | Country | Country Code | Constituency | Built Area | Built SubDiv |
| E16 1AG | 51.505982 | 0.015755 | 539995 | 180487 | TQ399804 | Newham London Boro | Royal Docks Ward | E09000025 | E05000491 | England | E99999999 | East Ham | Greater London | Newham |
Elasticsearch database and Sense Editor
We use elasticsearch version 1.1 to store our datasets; the database documentation is available here. Simply run it on your Java Virtual Machine and it'll start listening on port 9200 for HTTP requests.
home> sh <path-to-elasticsearch-folder>/bin/elastichsearch
A great tool for experimenting with elasticsearch queries is Google Chrome's browser plugin Sense. At the time being, the plugin developers seem to migrate it into a standalone version; you can follow the discussion here where you likely will find a link to a working copy.
Initial Index and warm up gymnastics
The job of a online minicab booker is to get the right customer location and destination to dispatch a cab. If a user always types in perfect address data then all we have to do is map the postcode to the location on the map and we're done. However, an online user expects some sort of feedback, or assistance, to help him find destinations effortlessly. Even misspelled addresses or partial input should be enough to find the right place.
This is where elasticsearch and the power of Lucene comes into play. It allows fuzzy searches and has built in support for geolocation searches. There are tens of Dock Roads in the UK and assuming the minicab company operates in London, we would like to sort them so that the ones in London have a higher rank. As with modern search engines, a search for "Doc Road" should give us results, even if no such road exists in the entire dataset.
This is how this kind of database technology differs from conventional relational SQL databases. Relational databases operate under the closed world assumption: any statement that is not known to be true is considered false. Example: "Dock Road" ia a road in "London". The question: Is "Doc Road" a road in "London?" would indeed assumed to be false. The answer we would like to see is: "I'm not sure, how about Dock Road or Dook Road?". Elasticsearch would come up with a list of roads to chose from instead of answering negative.
HTTP API
We communicate with the database server via HTTP calls; elasticsearch's queries are passed in the message body as structured JSON. For starters, let's get some http helper functions ready to let us get and post JSON.
import urllib
import urllib.request
import json
def POSTJsonString(url, query):
'''Get JSON Results with HTTP POST'''
rq = urllib.request.Request(url, query.encode('UTF-8'))
r=urllib.request.urlopen(rq).read()
rPrime = r.decode('UTF-8')
return json.loads(rPrime)
def POSTJson(url, query):
'''Get JSON Results with HTTP POST'''
...
def GETJson(url):
'''Get JSON Results with HTTP GET'''
...
Indexing
In elasticsearch parlance, indexing data is pushing data into the DB. Both CSV files could use some restructuring at the file level, yet we chose to index them right now and do restructuring through elasticsearch API calls.
Using the index API we can quickly index a single postcode form the Doogal dataset:
PUTJson('http://localhost/os/postcodes/e161ag',{ "postcode" : "E16 1AG", "latitutde" : "0.01", ... }
This is the structure of the document path:
- Index name: os
- Type: postcodes
- ID: e161ag
Here's a naive implementation that does the same for the whole dataset. It'll issue over 2.5 million HTTP requests!
f = open('.\\datasets\\postcodes.csv','r')
r = f.readline()
while r:
rs = r.split(',')
PUTJson('http://localhost/os/postcodes/' + str(rs[0]).lower().replace(" ", ""),{
"postcode" : str(rs[0]),
"latitutde" : str(rs[1]),
"longitude" : str(rs[2]),
"easting" : str(rs[3]) ,
...
"constituency":str(rs[13])
})
r=f.readline()
f.close()
If we do the same with the roads file then we're ready to test some initial queries. As we'll see later, there are more efficient ways to push a bulk of data into the database.
Basic querying
The most basic search is by direct path to the object; there's no query body required when getting data by ID. Let's fire up Sense and issue our first query. Sense accepts input in the left panel and output is shown to its right.
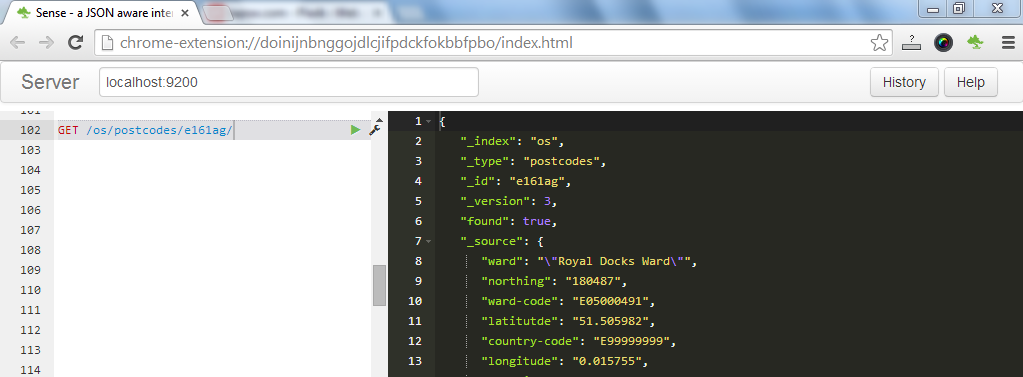
The elasticsearch query DSL defines several query types (and filters), one of which is the match query. It expects a field and a search term. There's one special field named "_all" that contains a concatenation of all fields of our object. Our query now asks for all objects that contain either the string "e16" or "1ag" among its fields. Notice that the result set, called hits, is over 2K large, yet our object is found at the top of the list with the highest result score.
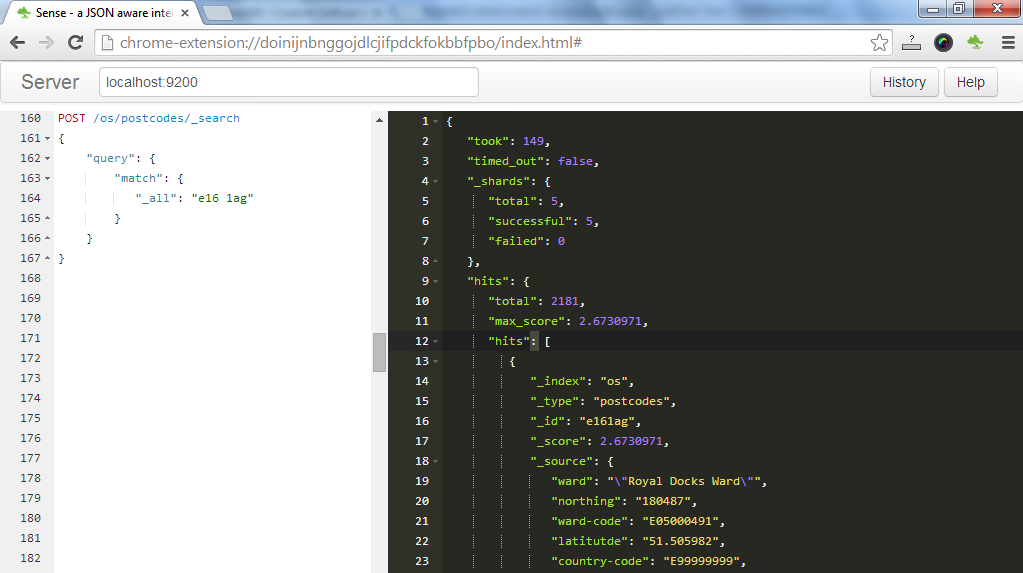
Restructuring the DB - Bulk operations
There's a great deal of queries that we can run on both our postcode and road types. Our naive initial indexing, however, doesn't allow us for juicier queries such as "find all postcodes in a radius of 3km of some arbitrary point". Elasticsearch understands geo queries; but, it can't work with our lat lon string types.
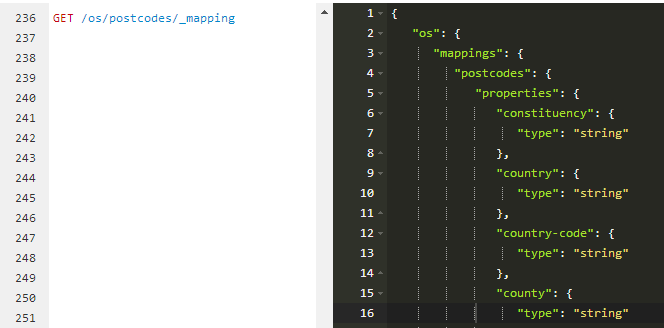
All data type information is maintained in a mapping.
To get the mapping of the postcode simply run GET /os/postcodes/_mapping in Sense.
As you can see, elasticsearch inferred the basic data-type "string" at index time.
What we need to do is to re-index the dataset and create a geopoint data-type, which elasticsearch can handle. This is a great opportunity to introduce bulk operations; we're concerned with two particular operations: batch reading and bulk writing. Our goal is to get the whole index in batches, manipulate each batch, and submit it back to the index in bulk.
Scan scroll - get data in batches
In order to read batches we use the scan scroll API. To initialise batch reading we issue an initial scan&scroll request that contains the query. It doesn't return any matches but returns an Unique ID instead that must be passed as a parameter in subsequent scroll requests. The subsequent scroll requests return data pages along with fresh IDs to submit along with requests for the further pages.
We've put the two operations in two functions. Notice that the first one submits a query asking for the whole dataset and returns a tuple containing the size of the datataset and the ID. The second function takes this ID as an input and returns a tuple containing the data page and a fresh ID. Every time the second function is invoked we must pass along the fresh ID returned by the previous invocation.
def initScrollRequest (typePath, batchSize) :
""" typePath: string such as "os/postcodes" """
query = {'query': {'match_all': {}}};
result = POSTJson("http://localhost:9200/"+typePath+"/_search?search_type=scan&scroll=10m&size="+str(batchSize), query);
return {
"scrollIndex":result['_scroll_id'],
"totalIndexRecords":result["hits"]["total"]
}
def scrollDataRequest (scrollIndex) :
""" scrollIndex: returned by initScrollRequest and by this function """
result = GETJson("http://localhost:9200/_search/scroll?scroll=10m&scroll_id="+scrollIndex)
return {
"dataHitsList":result["hits"]["hits"],
"scrollIndex":result["_scroll_id"]
}
Bulk updates
The bulk API essentially allows us to string together multiple index, update, or delete requests and push them into ES in one go. In this example we've created a string containing information for two postcodes.
{"index": {"_index":"os","_type":"postcodes","_id":"e161ag"} } ) \n
{
"ward": "\"Royal Docks Ward\"",
"northing": "180487",
"ward-code": "E05000491",
"latitude": "51.505982",
...
}\n
{"index": {"_index":"os","_type":"postcodes","_id":"e161ah"} } ) \n
{
"ward": "\"Royal Docks Ward\"",
"northing": "180487",
"ward-code": "E05000491",
"latitude": "51.505982",
...
}\n
...
Let's assume that the previous example is of type "string" and call it bulkstring.
To send it to elasticsearch simply do:
POSTJsonString("http://localhost:9200/_bulk", bulkstring)
Our initial postcode indexing would benefit tremendously from pushing data in bulk rather than issuing over than 2.7 million http requests.
Indexing the geopoint datatype in bulk
Now that we know how to read and write in big batches, what we'll do is re-index our postcodes type so that lat-lon coordinates are mapped to the geopoint type. Before doing this, we head over to Sense and add the appropriate mapping
PUT /os/postcodes/_mapping
{
"pin": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
The following script is reading our postcode type in batches and stringing together the call for bulk indexing.
s = initScrollRequest("os/postcodes", 100)
sP= scrollDataRequest(s["scrollIndex"]) #get first batch
while (len(sP["dataHitsList"]) > 0 ):
try:
bulkString = ""
for hit in sP["dataHitsList"] :
try:
lon = float(hit["_source"]["longitude"])
lat = float(hit["_source"]["latitutde"])
hit["_source"]["location"] = {"lon":lon,"lat":lat} #geopoint
bulkString += json.dumps (
{"index":
{"_index":"os","_type":"postcodes","_id":hit["_id"]}
} ) + "\n"
+ json.dumps (hit["_source"]) +"\n"
except KeyError:
#error handle
#endfor
POSTJsonString("http://localhost:9200/_bulk", bulkString)
sP = scrollDataRequest(sP["scrollIndex"]) #get new batch
except :
#error handle
We are now in a position to ask for nice things such us "get all postcodes around a specific point on the map"
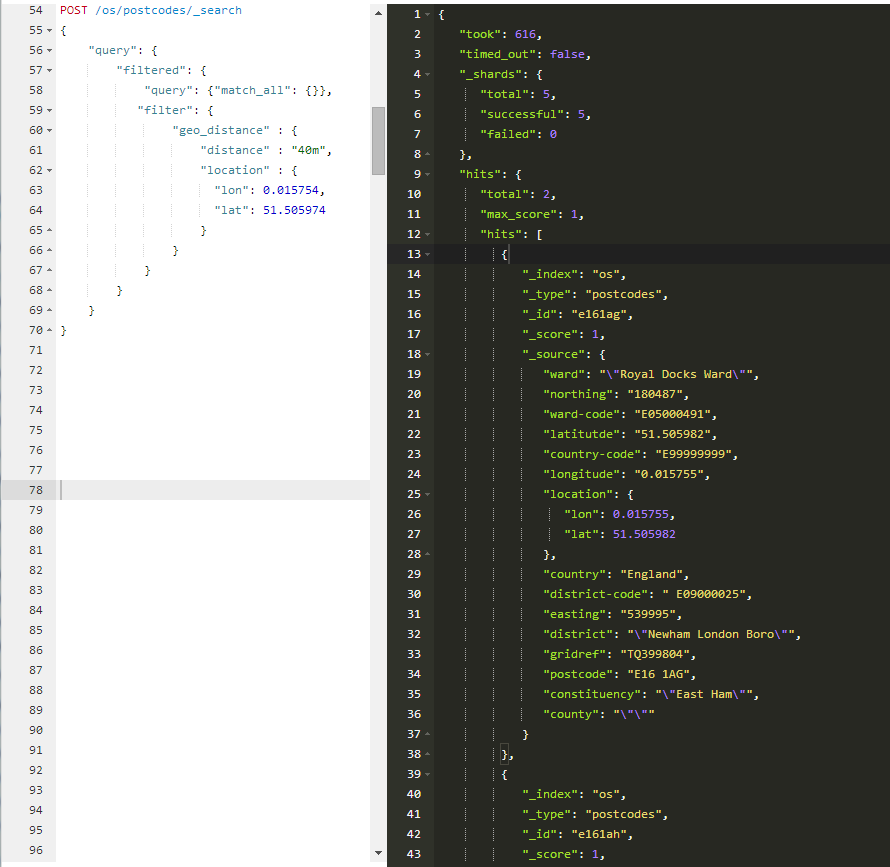
The query that we issued is a filtered query with a geo_distance filter applied; it correctly found the two postcodes of the tapSW HQ.
Add postcodes to roads
We repeat the same steps to re-index the roads type where we convert min, max, and centerpoint coordinates of the road bounding box into the geopoint data-type. The only difference is that the file uses northing and easting, instead of lat-lon coordinates. Elasticsearch doesn't seem to handle this coordinate system yet. The discussion here (script included) shows you how to convert between the coordinate systems.
The only logical connection between the two types in our index is via their the geo-coordinates. We could craft a complex query to validate the relationship between a road-name and a postcode; however, we chose to trade size for speed and store all postcodes that are close to a particular road into each road object. For each road, we are going to pull all related postcode IDs and store them in a property of type 'list'.
That's not as straightforward as it seems. Let us put the information included in the Dock Road entry on a real map. The bounding box of the road object is the one defined in the min and max coordinates. Notice, however, that our postcode is not included in that bounding box --- it doesn't have to. Thus, feeding the min-max coordinates to a geo bounding box filter wouldn't do the job. Also, consider the tiny area the bounding box would cover for perfectly vertical or horizontal roads!
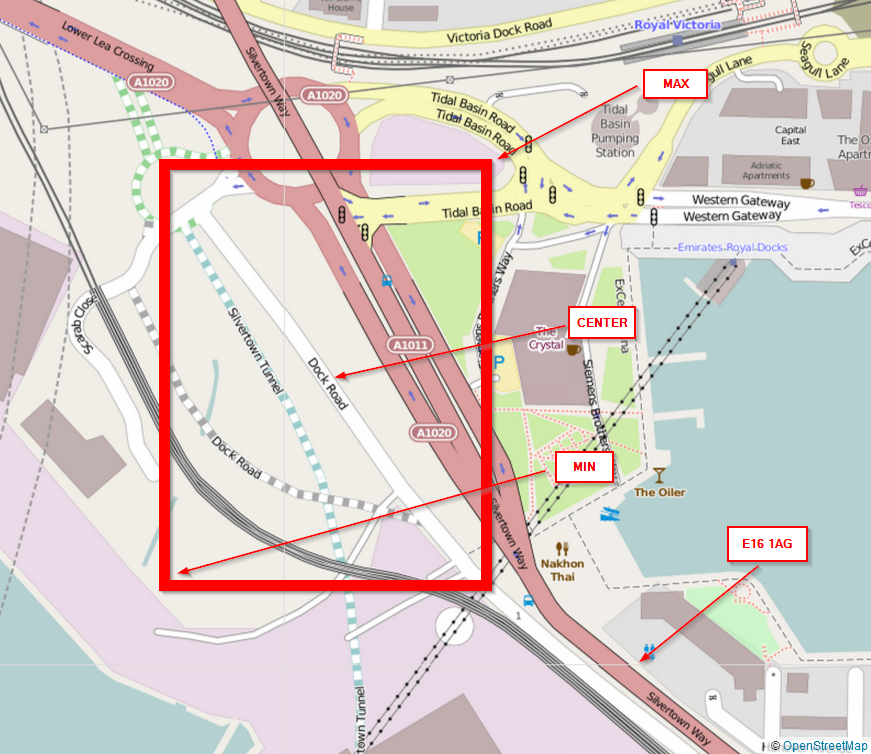
We prefer to use the distance filter from before; but, we have to settle with an acceptable radius to get the stray postcodes. Let's take the bounding box diagonal, in kM, which is easily calculated by the harvesine formula. Here's a python version of this SO solution
import math def getDistanceFromLatLonInKm(lat1,lon1, lat2,lon2): R = 6371; # Radius of the earth in km dLat = deg2rad(lat2-lat1) dLon = deg2rad(lon2-lon1) a1 = math.sin(dLat/2) * math.sin(dLat/2) a2= math.cos(deg2rad(lat1)) * math.cos(deg2rad(lat2)) * math.sin(dLon/2) * math.sin(dLon/2) s= a1 + a2 c = 2 * math.atan2(math.sqrt(s), math.sqrt(1-s)) d = R * c # Distance km return d def deg2rad (deg) : return deg * (math.pi/180)
According to this, our radius should be 332m or 0.332 km. Thus, if we take the center-point as a starting point then the Sense query for postcodes would be
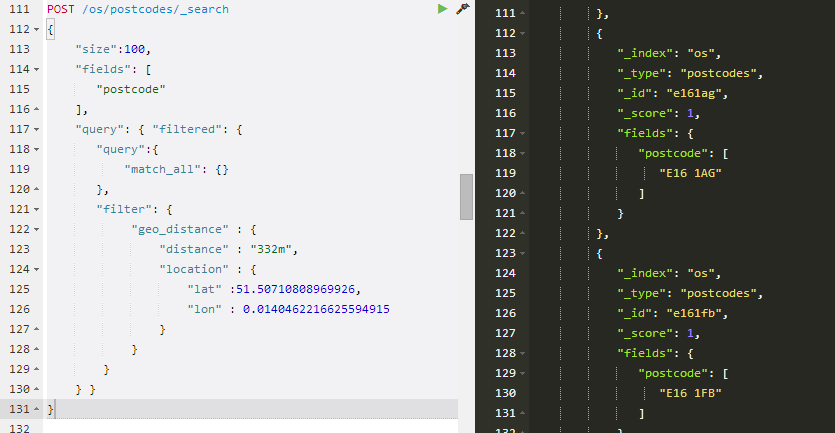
But, you may say, this will get a lot of postcodes from the Silvertown Way in there. That's true, but as with any search engine today, the user has learned to easily filter through such false positives.
Wrapping Up
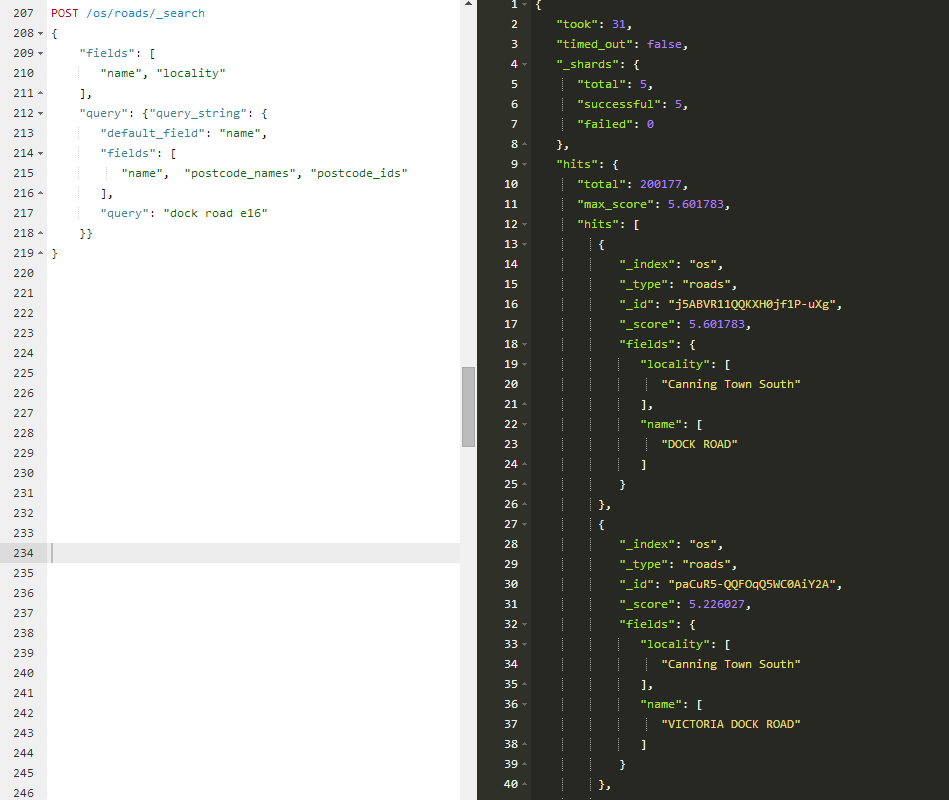
That's now the final peace to the puzzle. Here's the algorithm. For each road object, take the centre point, do a radius search, stick in all found postcodes and let this run overnight.
...
We now allow for very high level queries indeed:.
Contact
Theory and Practice of Software
G35 Waterfront Studios1 Dock Road, London, United Kingdom E16 1AG, United Kingdom
Use contact widget at the bottom right corner.